End to end methods for Autonomous Driving as a beginner (LLM approach)

I look back at the assisted driving systems project I created during my undergraduate studies. As we continue to improve it, it is gradually becoming more bloated and difficult to scale. As I continued to learn, I found that an end-to-end approach would be the right solution. In this page, I will record my review of this project and my gradual understanding of the end-to-end approach as a beginner.

In this page, I first review the assisted driving project I once created and explain how it was structured. Then I will introduce World Model as a novice and introduce the advantages of LLM for autonomous driving. Next, I will share a paper on how to integrate LLM into an autonomous driving system. Finally, I will go deeper into Augmented Language Models and share how I begin.
A look back
In the past year, I tried to launch an assisted driving project and formed a team. After a period of hard work, we created an assisted driving system from scratch with many parts, including in-vehicle edge computing devices, sensor groups (including cameras, Lidar and ultrasound), in-vehicle central control interactive applications, User backend, and user APP. Looking back at this project, I admit that our technology was very backward - at least not cutting-edge. We use multiple computer vision models to process information from sensors, including semantic segmentation (used to segment drivable areas), object detection and monocular depth estimation (used to estimate vehicle distance), and a lane line detection model, and illegal driving detector.
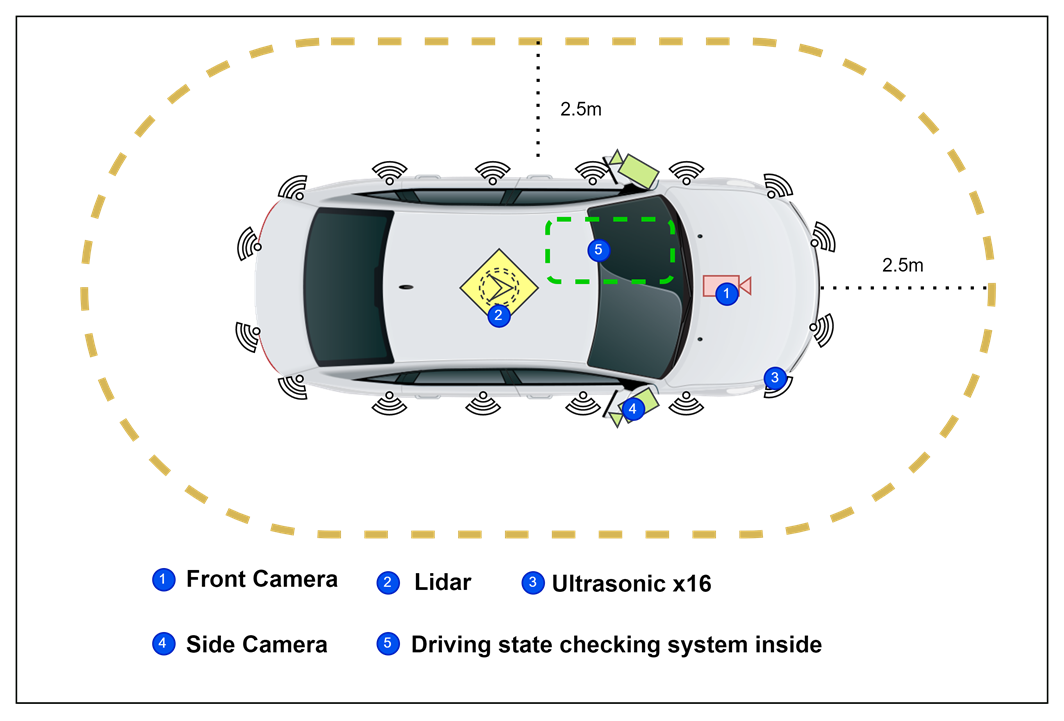
I structured this project in a very intuitive way. I used a traditional spot scanning lidar (I know there are solid state lidars but I don't own one) on the roof of the car and placed ultrasonic sensors all around the car. I placed a stable high frame rate camera in front of the car as a forward view. In addition, there is a camera in the car to detect the driver's status. We also developed various hardware related to it, but that is irrelevant to the topic of this discussion.

The figure above shows that in my previously proposed architecture, I had the various parts working separately. Especially the Edge Computing Device, on which I had to run multiple models at the same time to implement most of the assisted driving functions. Although it at least has these functions, it inevitably brings a lot of problems.
Motivation
Such an immature architecture makes it difficult for the project to continue to develop. I think the reasons are as follows:
- The optimization goals between multiple modules are inconsistent, and the decision maker has to be readjusted for the adjustment of each module. At the same time, local optimization of modules does not mean global optimization. The more modules there are, the more difficult it becomes to adjust the system.
- The calculation of the module has considerable redundancy. Although I have optimized it from the software level, for example, dynamically allocating computing resources to required modules. But in order to ensure the real-time nature of the information, it becomes very difficult to continue optimizing, especially when our goal is to use edge computing device deployment.
- The input, output and intermediate processes of the entire system are very complex, and the difficulty of maintenance is gradually increasing.
So I started thinking about solutions to the above problems. I came to understand that an end-to-end approach could solve my problem from multiple perspectives. I drew a diagram to represent the benefits of an end-to-end approach:
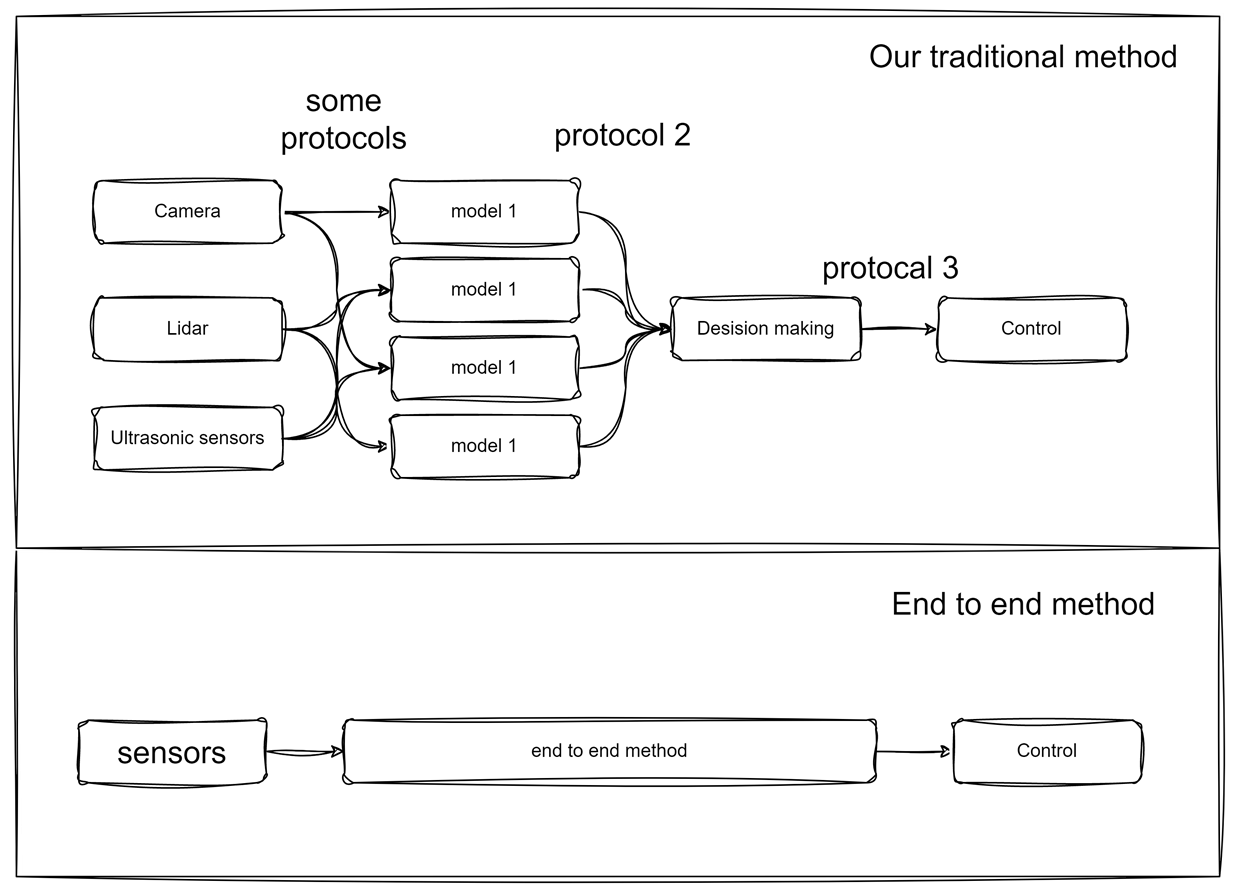
The end-to-end approach obviously has the following benefits:
- Eliminate the computing redundancy just mentioned and improve system speed and performance
- Eliminate cumulative errors caused by the existence of multiple modules
- The optimization goal becomes single, and all problems can be solved in a single training session
- It is no longer necessary to design too many rules in the decision maker, data-driven training becomes possible
However, the end-to-end approach will also bring new challenges:
- The end-to-end approach is completely black box. Reliability and security issues as well as interpretability issues become challenges
- Although the optimization goal seems to become "single", in fact, the end-to-end method cannot directly learn the correct reasons for decision-making. For example, the decision-making method learned at a traffic light intersection using a data-driven model is to start when the car in front starts to move, rather than when the red light ends (because the car in front will move when the red light ends)
In any case, the end-to-end approach is a topic that I cannot avoid as I continue to learn. Therefore, I will start to gradually understand the end-to-end autonomous driving method as a beginner. On this page I will record my experience as I gradually learn about each technology and individual components.
The world model
In the context of autonomous driving, a "world model" typically refers to a representation of the environment in which the autonomous vehicle operates. A world model learns a structured representation and understanding of the environment that can be leveraged for making informed decisions when driving. However, for a beginner, World Model is not quickly understood. In the context of autonomous driving, a "world model" is not a simple model but a complex system. It's a comprehensive and dynamic representation of the environment in which an autonomous vehicle operates. This representation encompasses various components, including sensor data processing, object detection, map representation, localization, and more. These components work together to create a rich and detailed understanding of the vehicle's surroundings.
In order for people reading this page to quickly understand how World Model works, I will share a paper that gives a feasible implementation of World Model: [2309.17080] GAIA-1: A Generative World Model for Autonomous Driving (arxiv.org) , a generative world model for autonomous driving that leverages video, text, and action inputs to generate realistic driving scenarios.
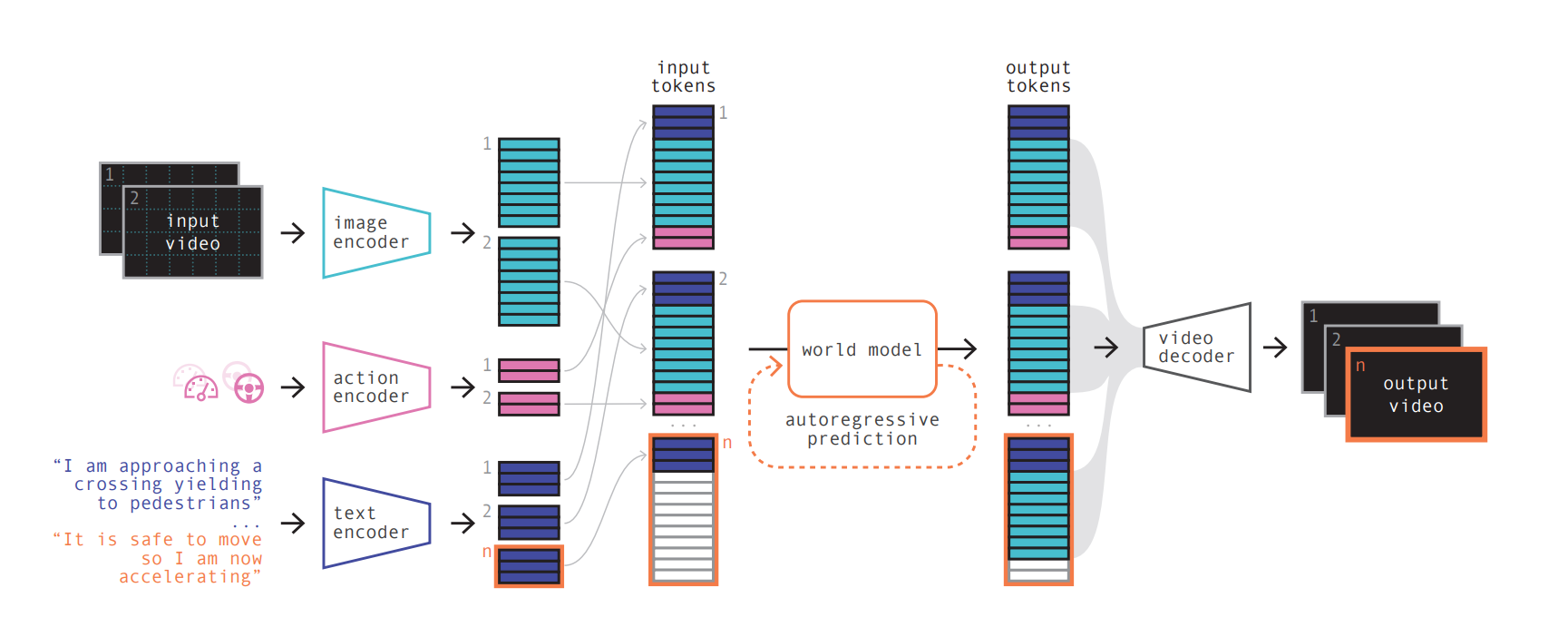
Please check the position of the World Model in the above Figure and its relationship with other components. As you can see, World Model in this implementation accepts multiple structured inputs and gives output tokens as output. The input of a world model in the context of autonomous driving is typically a wide range of sensor data that provides information about the vehicle's surroundings and its own state. The primary sources of input data for a world model including but not limited to:
-
Cameras: Cameras capture visual information and are used for tasks like lane detection, object recognition, and traffic sign recognition.
-
LiDAR (Light Detection and Ranging): LiDAR sensors emit laser beams to measure distances to objects and create detailed 3D point cloud representations of the environment. LiDAR data is crucial for object detection, obstacle avoidance, and mapping.
-
Radar: Radar sensors use radio waves to detect the presence and speed of objects, making them valuable for tracking moving vehicles and objects, especially in adverse weather conditions.
-
GPS (Global Positioning System): GPS provides information about the vehicle's absolute position and can be used for localization and route planning.
-
IMU (Inertial Measurement Unit): IMU sensors measure the vehicle's acceleration and orientation, helping to estimate the vehicle's ego state.
-
Wheel Encoders: These sensors track the rotation of the vehicle's wheels, aiding in estimating the vehicle's speed and distance traveled.
-
High-Definition Maps: High-definition maps provide a static reference for the road geometry, lane boundaries, traffic signs, and other infrastructure. These maps are used for localization and navigation.
The world model integrates and processes data from these sensors to create a coherent representation of the environment. The input data is processed to identify and track objects (e.g., other vehicles, pedestrians, obstacles), understand the road layout, and continuously update the vehicle's own state within the environment. This processed data is then used to make real-time decisions and enable the safe and efficient operation of the autonomous vehicle. The integration of data from various sensors is a key aspect of building an accurate and reliable world model, and it often involves sensor fusion techniques to combine the strengths of different sensor modalities.
Therefore, a simple conclusion is that World Model accepts any input related to driving status and environment and gives any output related to driving. Since the currently popular encoders (for example, Transformer) have strong adaptability, as long as enough structured input and labels are given, a world model with the input and output you want can be trained. What ultimately determines the world model is the data itself, that is, the world model depends on what kind of data you provide. This is a challenge, but it also provides the possibility of a data-driven approach and end to end methods.
If you are a real beginner, Don't try to understand World Model and Generative Model as the same thing. The model described in the information is considered a generative model because it has the ability to generate realistic video samples of driving scenarios. It can generate multiple plausible futures based on a given video context and can also generate frames conditioned on specific attributes such as weather or illumination. The model mentioned above uses a world model approach, which is a predictive model of the future that learns a general representation of the world to understand the consequences of its actions. By leveraging this world model, the model can generate driving scenarios that it has not seen in the training data, indicating its ability to extrapolate driving concepts. The model is designed to address the challenge of predicting future events in real-world scenarios and offers fine-grained control over ego-vehicle behavior and scene features. But that has nothing to do with our topic this time. I just want to use an implementation form given in this paper to let you quickly understand the location of the World Model and its relationship with other components.
LLM for autonomous driving (LLM4AD)
LLM-for-Autonomous-Driving (LLM4AD) refers to the application of Large Language Models(LLMs) in autonomous driving. LLM becomes special medicine in some situations, that is, **LLM can use common sense to assist decision-making and has strong interactive capabilities. It was also able to handle unstructured data(for example, ethical and moral issues or decision-making under complex conditions) easily, and detect as well as provide feedback on driving behavior **, even other capabilities that the system I had envisioned was not capable of. Therefore, I started searching for successful cases of LLM applied to autonomous driving.
I went through the survey [2311.01043] A Survey of Large Language Models for Autonomous Driving (arxiv.org) and found it is of great significance that I would like to share it with anyone who is reading this page. In the survey of large language models (LLMs) for autonomous driving, the authors discuss the transition from rule-based systems to data-driven strategies in autonomous driving technology and the limitations of traditional module-based systems. The paper highlights the potential of LLMs in empowering autonomous driving by combining them with vision models to enable open-world understanding, reasoning, and few-shot learning. The authors systematically review the current state of LLMs for autonomous driving, outline the challenges and future directions in the field, and provide real-time updates and resources for researchers. The paper also discusses the motivation behind using LLMs in autonomous driving and the application of LLMs in planning, perception, question answering, and generation tasks.
In short, the main points are:
- Autonomous driving is transitioning from rule-based systems to data-driven strategies.
- Traditional module-based systems have limitations due to cumulative errors and inflexible rules.
- Large language models (LLMs) have the potential to empower autonomous driving by combining them with vision models.
- LLMs can enable open-world understanding, reasoning, and few-shot learning. LLMs can be applied in planning, perception, question answering, and generation(e.g. the world model) tasks in autonomous driving.
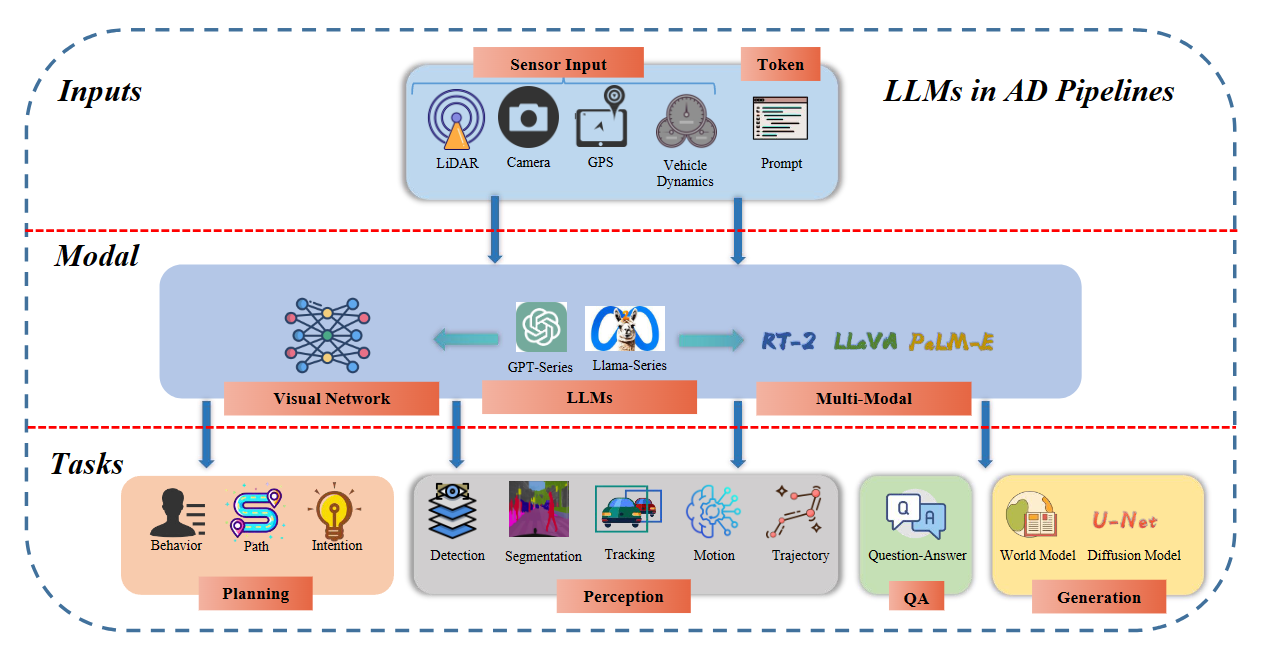
Moreover, according to the paper, LLMs can be integrated into autonomous driving pipelines to enhance various aspects of the system's capabilities. Here is a breakdown of how LLMs are applied in different areas of autonomous driving pipelines and the evaluation metrics used in different research papers related to autonomous driving and large language models:
-
Perception: LLMs can be used for perception tasks such as object detection, tracking, and segmentation. By integrating LLMs with visual networks, multimodal models can be created to improve the system's perception abilities.
Different metrics are used to evaluate perception tasks such as object detection, tracking, and segmentation. These include Average Multiple Object Tracking Precision (AMOTP), Average Multiple Object Tracking Accuracy (AMOTA), Identity Switches (IDS), BLEU-4, METEOR, CIDER, SPICE, and IoU (Intersection over Union).
-
Planning: LLMs can assist in the planning stage of autonomous driving. This involves using LLMs for decision-making, behavior prediction, path planning, and motion trajectory generation. LLMs can provide open-world cognitive and reasoning capabilities, enabling the system to make more informed and context-aware decisions.
Metrics used for evaluating planning tasks include Root Mean Squared Error (RMSE), threshold accuracies, and success rates. Additionally, metrics like L2 error (in meters) and collision rate (in percentage) are used to measure the accuracy and safety of planned trajectories.
-
Question Answering: LLMs can be utilized for question-answering tasks related to autonomous driving. This involves using LLMs to understand and respond to queries about the driving environment, vehicle dynamics, and other relevant information.
For evaluating question-answering tasks, metrics commonly used in natural language processing (NLP) are employed. These include BLEU-4, METEOR, CIDER, and chatGPT score.
-
Generation: LLMs can be employed for generating various outputs in autonomous driving systems. This includes generating driving instructions, explanations for the system's actions, and other forms of natural language generation.
In the context of generating driving scenarios or videos, metrics such as BLEU-4, METEOR, CIDER, and SPICE are used to assess the quality and realism of the generated content.
LLM understands the driving environment
The relationship between LLM4AD and World Model is that LLMs can be applied in the World Model of autonomous driving systems to enhance their capabilities, or LLMs can be the World Model themselves.
The World Model refers to the representation of the environment and the vehicle's understanding of it and LLMs can enhance the World Model by providing open-world understanding, reasoning, and few-shot learning capabilities. By combining LLMs with foundation vision models, autonomous driving systems can benefit from the extensive knowledge base and generalization capabilities of LLMs. This integration allows for better perception of the environment, more accurate prediction of future states, and improved decision-making.
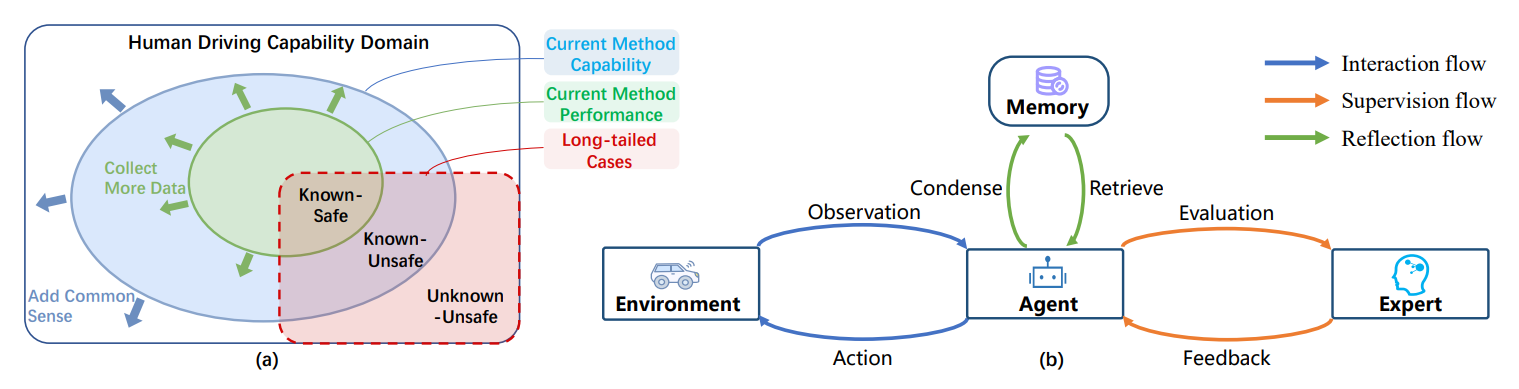
In [2307.07162] Drive Like a Human: Rethinking Autonomous Driving with Large Language Models (arxiv.org), the author uses multiple simple and easy-to-understand examples with example pictures to fully illustrate how LLMs cope with various traffic scenarios. The paper explores the potential of using large language models (LLMs) to understand the driving environment in a human-like manner. The authors argue that traditional optimization-based and modular autonomous driving systems face limitations when dealing with complex scenarios and long-tail corner cases. To address this, they propose that an ideal autonomous driving system should drive like a human, accumulating experience through continuous driving and using common sense to solve problems. The paper identifies three key abilities necessary for an autonomous driving system: reasoning, interpretation, and memorization. The authors demonstrate the feasibility of employing an LLM in driving scenarios by building a closed-loop system to showcase its comprehension and environment-interaction abilities. The experiments show that the LLM exhibits impressive reasoning and problem-solving abilities, providing valuable insights for the development of human-like autonomous driving.
This article does a great job of explaining a lot of my dissatisfaction with the system I originally constructed:
- Traditional optimization-based and modular autonomous driving systems face limitations with complex scenarios and long-tail corner cases.
- An ideal autonomous driving system should drive like a human, accumulating experience and using common sense.
- There are three key abilities necessary for an autonomous driving system: reasoning, interpretation, and memorization.
The paper points out that LLMs can be employed in driving scenarios to achieve human-like driving and demonstrate impressive reasoning and problem-solving abilities in handling complex scenarios and long-tail corner cases.
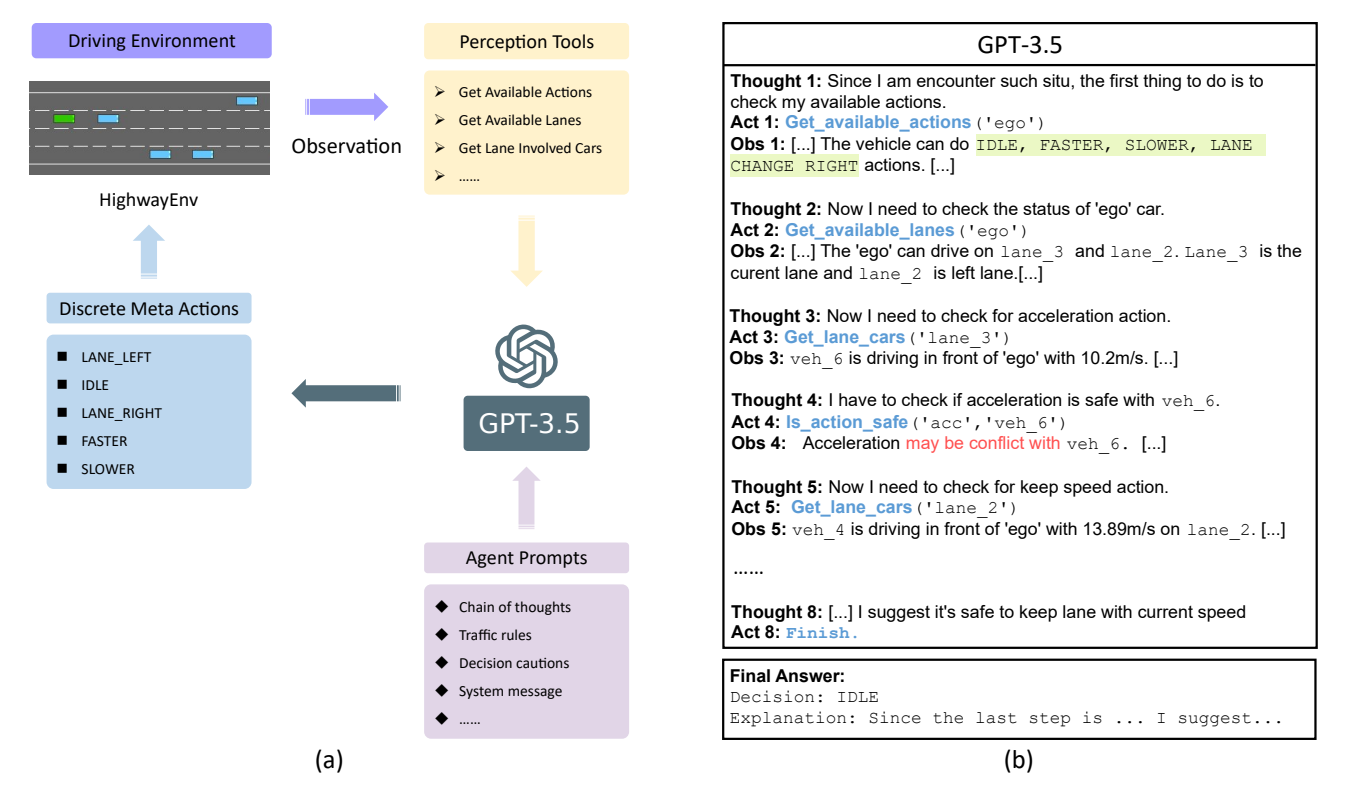
In the above figure, the author uses a simple traffic scene to show how GPT3.5 handles driving on the highway. In the paper, the author also introduces various other situations, such as lane-change decision-making process, and introduces the self-reflection and memorization ability of LLM. If you want to refer to other examples, check out this paper.
Combining LLMs into the system
Here is an interesting example of how to adapt LLM into an autonomous driving system.
[2310.01957] Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving (arxiv.org) introduces a unique object-level multimodal Large Language Model (LLM) architecture for autonomous driving. The author proposes a methodology for integrating numeric vector modality into pre-trained LLMs to improve context understanding in driving situations.
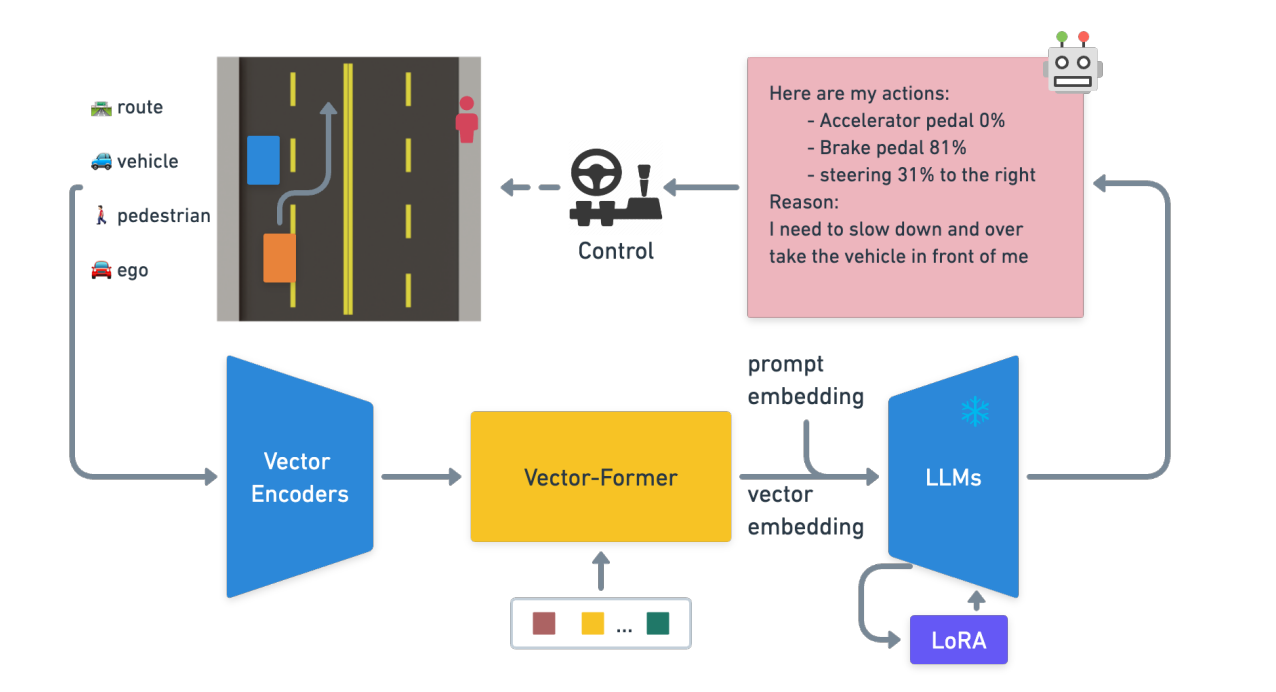
The main contributions of the paper include the novel object-level multimodal LLM architecture, the driving scenario question-answering task and dataset, and the evaluation metric for driving QA. The paper also discusses related works in end-to-end autonomous driving systems, interpretability of autonomous driving systems, and multi-modal LLMs in driving tasks. The paper present a new dataset of 160k question-answer pairs derived from 10k driving scenarios, paired with high-quality control commands collected with a reinforcement learning (RL) agent and question-answer pairs generated by a teacher LLM.
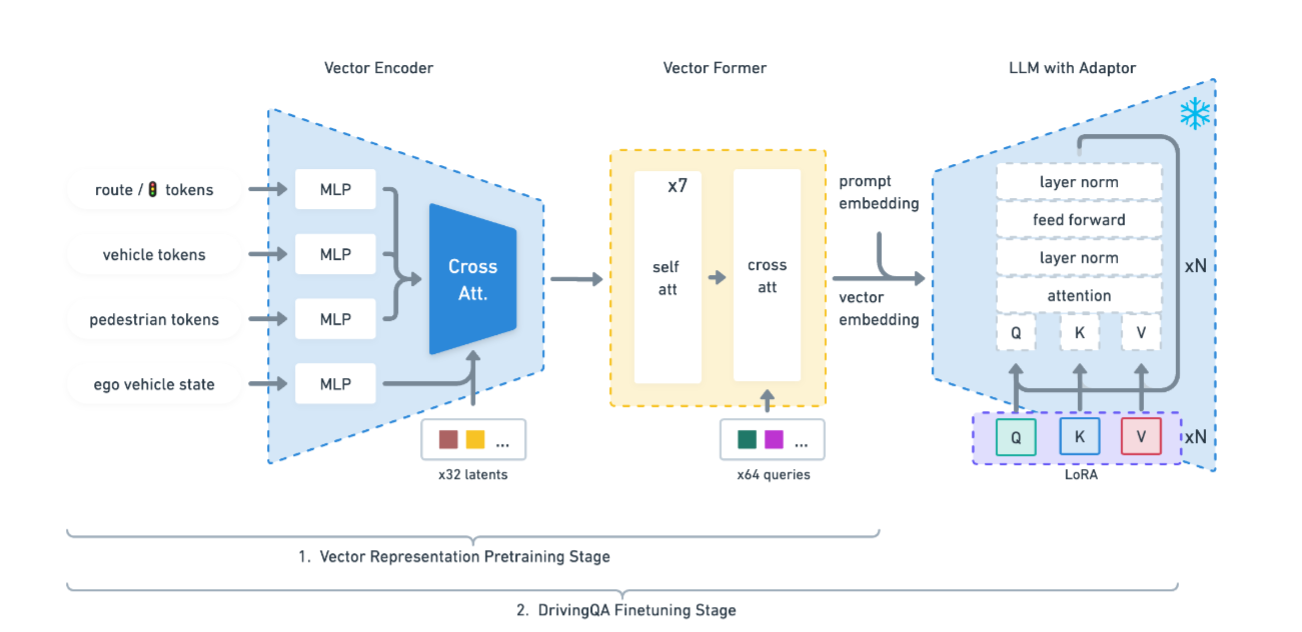
To be specific about adapting the proposed methodology, it involves aligning numeric vector modalities with static LLM representations using vector captioning language data. A custom 2D simulator is used to train an RL agent to solve driving scenarios, and a language generator is introduced to translate numerical data into textual descriptions for representation pretraining. A teacher LLM is used to generate question-answer pairs conditioned on the language descriptions of different driving scenarios.
The training of the Driving LLM Agent involves a two-stage process. In the first stage, the vector representation is grounded into an embedding that can be decoded by the LLMs. In the second stage, the model is fine-tuned to the Driving Question Answering (DQA) task, training it to answer driving-related questions and take appropriate actions based on its understanding of the environment.
During inference, the input data of the proposed model consists of object-level vectors that describe various aspects of the driving scenario. These vectors are structured and organized into different categories. Here is a breakdown of the input data:
- Route Descriptors: A 2D array per ego vehicle that describes the route to follow. Each route point is represented by a new row and includes attributes such as (x, y, z) coordinates, direction, pitch, speed limit, junction information, road width, traffic light state, and roundabout information.
- Vehicle Descriptors: A 2D array per ego vehicle that describes nearby vehicles. The array is allocated with a fixed maximum size (around 30) and contains information about each nearby vehicle. Attributes include whether a vehicle is present in the row, dynamic or static nature, speed, relative position in ego coordinates, relative orientation, pitch, size, and vehicle class.
- Pedestrian Descriptors: A 2D array per ego vehicle that describes nearby pedestrians. Similar to vehicle descriptors, the array is allocated with a fixed maximum size (around 20) and contains information about each nearby pedestrian. Attributes include whether a pedestrian is present in the row, pedestrian speed, relative position in ego coordinates, relative orientation, pedestrian type, and intent of crossing the road.
- Ego Vehicle Descriptor: A 1D array per ego vehicle that describes the state of the ego vehicle. This includes attributes such as vehicle dynamics state (acceleration, steering, pitch, etc.), vehicle size, vehicle class, vehicle dynamics type, previous action, and lidar distance arrays placed on the front corner of the vehicle.
These object-level vectors are fed into the model to generate predictions and responses related to the driving scenario. The model utilizes the information encoded in these vectors to reason about the driving environment, make decisions, and generate outputs that can be explained based on its internal reasoning. The structured output includes perception and action predictions. The model predicts perception-related information such as the state of nearby vehicles, pedestrian presence, and the state of the ego vehicle. It also predicts action-related information such as the anticipated future actions of the ego vehicle based on the driving scenario.
The paper also evaluates the perception and action prediction capabilities of the model. The results show that the pretraining stage significantly enhances the model's perception and action prediction capabilities. The pretrained model exhibits higher accuracy in perceiving and quantifying the number of cars and pedestrians and shows improvement in token predictions.
Learning to use tools and act
An Augmented Language Model (ALM) refers to a language model that is enhanced with the ability to leverage external tools and actions. Unlike regular language models that focus on computing the probability of the next word given the previous words, ALMs consider all possible tool uses in addition to the context. This introduces a trade-off between memorizing information in the model weights and utilizing external tools.
When LLM participates in assisted driving as a decision maker, its essence is a model using tools (here the tools specifically refers to the vehicles) and interact with the users, as well as interact with the world. In the survey [2302.07842] Augmented Language Models: a Survey (arxiv.org), the author reviews works in which language models (LMs) are augmented with reasoning skills and the ability to use tools. The authors refer to these models as Augmented Language Models (ALMs). The survey discusses different strategies for reasoning, such as eliciting reasoning with prompting, recursive prompting, and explicitly teaching language models to reason. It also explores the use of tools, including calling another model (for instance, calling the vehicles' controller), information retrieval, computing via symbolic modules and code interpreters, and acting on the virtual and physical world (for example, interact with road scene).
Additionally, we can say the LM performs an action when the tool has an effect on the external world. The possibility to easily include tools and actions in the form of special tokens is a convenient feature of language modeling coupled with transformers.
The simple conclusions of the survey are:
- Language models can be augmented with reasoning skills and the ability to use tools.
- Augmented Language Models (ALMs) leverage these augmentations to expand their context processing ability.
- ALMs can use various external modules to reason, use tools, and even act.
That is to say, under ideal circumstances, the method to use LLM to control the vehicle is to add a decoder at the end of the LLM to decode the output given by the LLM into specific driving actions. There are many ways to decode, which can be based on onehot (of course, a behavior may also contain multiple actions, and there may be a better decoding method). In order to train such a decoder, it is also necessary to match an objective function (for example, using reinforcement learning)
The survey points out that Augmented Language Models (ALMs) have the ability to run code and experiments on behalf of a user, which a vanilla Language Model (LM) cannot do. ALMs can interact with external tools, entities, and environments to improve their reasoning and decision-making abilities. This interaction allows ALMs to collect additional information and ground themselves in the real world. However, ALMs also raise ethical concerns, as their predictions based on tools may appear trustworthy and authoritative, even when they are incorrect. The use of active tools, such as letting the LM control a search engine, can lead to harmful consequences without human validation. The development of ALMs represents a shift from passive LMs that generate text in isolation to ALMs that can act in the real world. The integration of reasoning and tools in ALMs is a promising research avenue for the next generation of deep learning systems capable of complex human-machine interaction.