Homework 1
Q1 Loop-carried dependences
For this question, we will describe a loop-carried dependence as coming from some statement in iteration (i,j) to some other iteration (x,y), where x and y are written as expressions involving i and j (e.g., (i,j+1)). For example, there could be a loop-carried dependence from S4(i,j) to S5(i+1,j). Note that the first statement must come before the second statement in program order.
Consider the code below, where all variables have been previously declared.
...
for (i=1; i <= N; i++) {
for (j=1; j <= i; j++) {
S1: a[i][j] = b[i][j] + c[i][j];
S2: b[i][j] = a[i-1][j-1] * b[i+1][j-1] * c[i-1][j];
S3: c[i+1][j] = a[i][j];
}
}
...
Thinking
- Finding dependencies inside iteration:
- Finding dependencies across iterations
- , normalized to
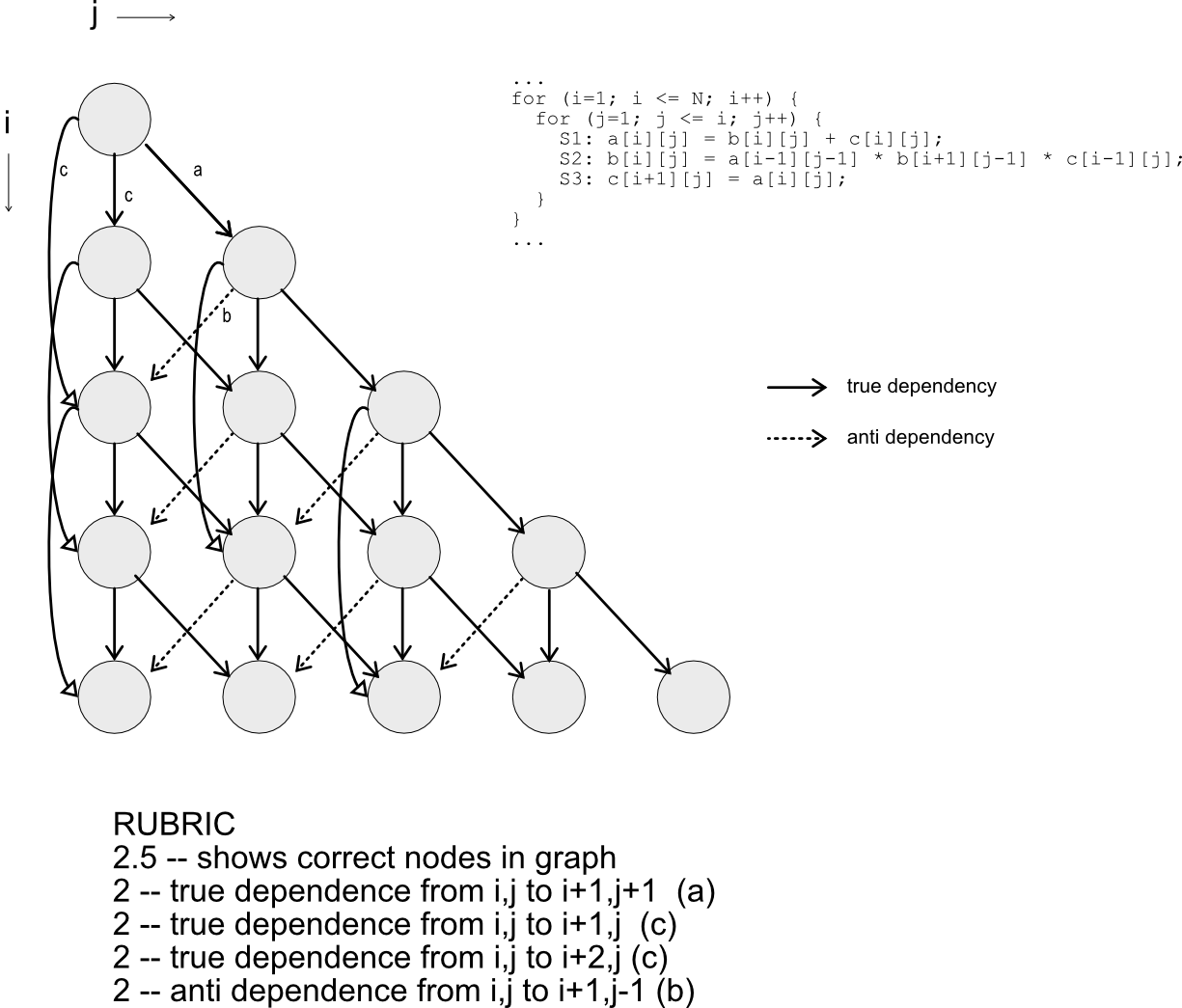
Q1.1 LDG Draw LDG for this loop nest
LDG does not reflect loop-independent dependency, each node in LDG represents all statements in a particular iteration. Therefore, only dependencies across iterations should be included:
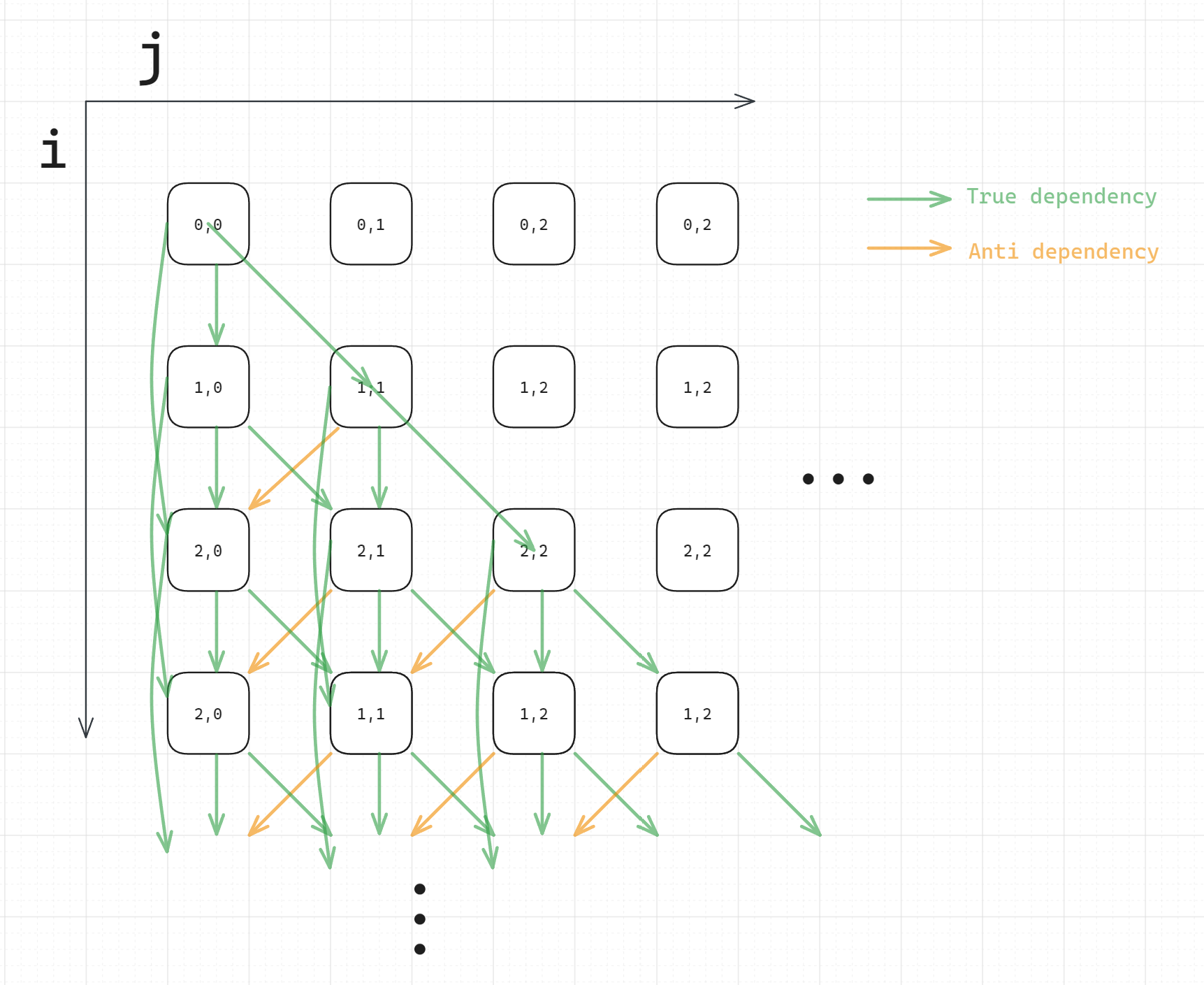 Figure: LDG of Q1
Figure: LDG of Q1
Notice that the loop variable j <= i, therefore, there are no data dependences below the diagonal of the graph.
[!success] Answer from TA
Q2 Variable scope analysis Consider the code below. All matrices have dimension , all vectors have dimension , and assume that is divisible by .
...
for (i=0; i<N; i++) {
k = C[N-1-i];
for (j=0; j<N; j++) {
A[i][j] = k * A[i][j] * B[i/2][j];
}
}
...
Q2.1 -loop By default, all variables are shared. If the -loop is converted to a parallel loop, indicate which variables should be private.
Thinking: Applying parallelism on loop, should be private to each thread, and things related to should be private too.
- : each thread should have its own . Make private.
- : its originally private if loop is parallel
- : its assigned within loop but not loop. Make private.\
- : its being read and written, but since the access index is private, then access to is thread safe. So can be shared.
- : its read only, can be shared.
- : its read only, can be shared. Therefore, , , are private.
Q2.2 -loop By default, all variables are shared. If the -loop is converted to a parallel loop, indicate which variables should be private.
Thinking: Applying parallelism on loop, should be private to each thread, and things related to should be private.
- : it has the same value and its read only for loops inside the same loop iteration, can be shared.
- : each thread should have its own . Make private.
- : same as , can be shared.
- : The same as loop parallelism, no race condition between different .
- : its read only, can be shared.
- : its read only, can be shared. Therefore, is private.
Q3 Average access latency Suppose you have a one-level (L1) cache. The L1 latency is 2 cycles, and memory latency is 80 cycles.
Q3.1 Calculate AAT If the L1 miss rate is 0.05, what is the average latency for a memory operation?
Q3.2 Calculate miss rate What must the miss rate be in order to achieve an average access latency of 10 cycles?
Q4 Average access latency (two-level) Suppose you have a two-level cache. The L1 access latency is 2 cycles. The L2 access latency is 10 cycles. The memory access latency is 80 cycles.
Q4.1 Calculate AAT If the L1 miss rate is 0.1, and the L2 miss rate is 0.5, what is the average access latency?
Q4.2 Calculate L2 miss rate If the L1 miss rate is 0.05, what must the L2 miss rate be to achieve an average access latency of 4 cycles?
Q5 Replacement policy
You have a fully-associative cache with a capacity of four blocks. Blocks are stored in positions 0, 1, 2, 3 in the set, from left to right in the figure. To write the content of the cache, list the block addresses in left-to-right order, and use a single hypen (-) to denote a block position that does not contain a valid block.
 Empty blocks are filled from left to right. As shown, the initial cache state is A,-,-,-.
Empty blocks are filled from left to right. As shown, the initial cache state is A,-,-,-.
The cache uses LRU replacement and has a write-no-allocate policy. After each memory operation below, show the state of the cache. Access sequence: Read B, Write A, Read C, Write D, Read C, Read E, Read D, Write C, Read B, Read F
It has a write no allocate policy, therefore write miss will not cause the block to be loaded into cache, only read miss will.
