Loop Level Parallelism
Loop Level Parallelism
DOALL Parallelism
Concept: DOALL In Do-All parallelism, all tasks are independent of each other and can be executed simultaneously. Each task does not depend on the outcome or results of any other task.

do-all is kind of data parallelism because data is split into parts for each . It's great for loops without dependency. For the code above it has no dependency on the first level loop.
for(size_t i=1; i<N; i++){
A[i] = B[i-1] + C[i]*2;
}
DOACROSS Parallelism
Concept: DOACROSS DOACROSS parallelism is a technique used to parallelize loops that have loop-carried dependencies (i.e., an iteration depends on the result of a previous iteration). It allows iterations to execute in parallel but introduces synchronization mechanisms to ensure correct execution order where dependencies exist.
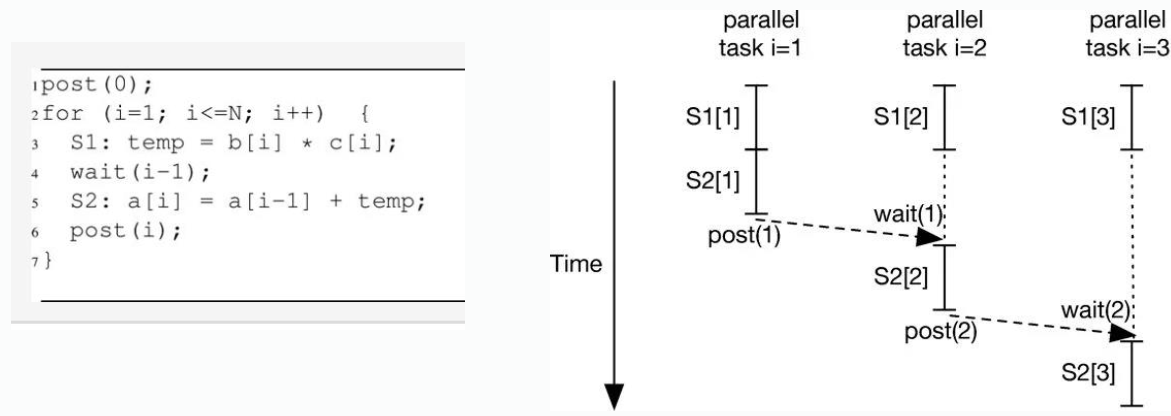 In do-across, some parts are parallel, but tasks need to wait on each other.
In do-across, some parts are parallel, but tasks need to wait on each other.
DOPIPE Parallelism
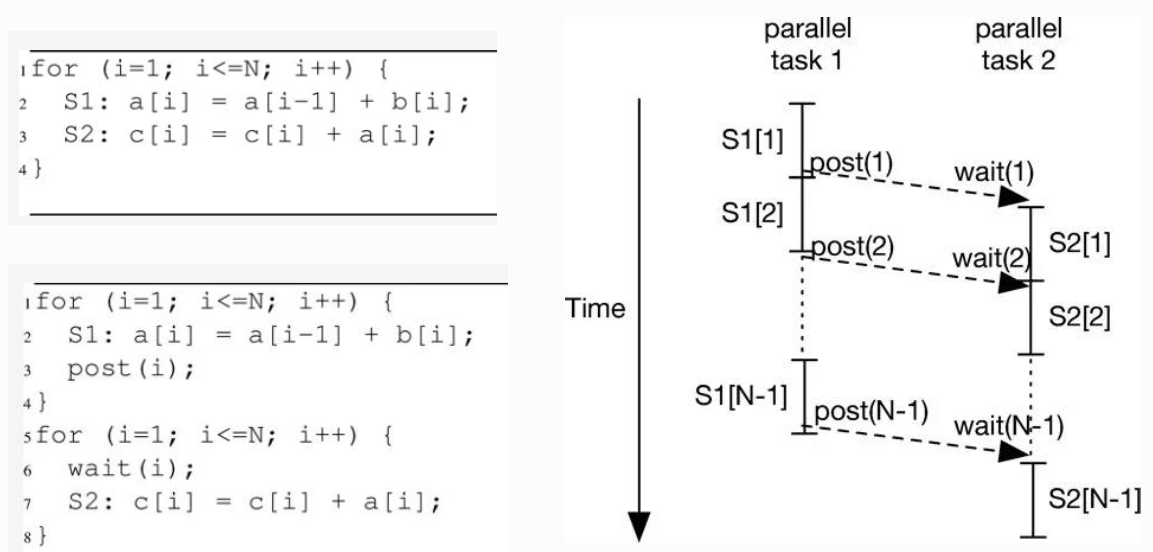
Concept: DOPIPE Do-Pipe (or Pipeline Parallelism) involves breaking a task into a series of stages, where each stage can be executed in parallel, often using a pipeline architecture. Each stage passes its result to the next stage.
Loop-Distribution Parallelism
Concept: Loop Distribution Loop distribution (also known as loop fission) involves splitting a loop into multiple loops over the same index range but with non-dependent computations separated. This technique exposes parallelism by isolating independent operations, allowing them to be parallelized using DOALL parallelism (where iterations are independent).
// Original loop with independent operations
for (int i = 0; i < N; i++) {
A[i] = B[i] + C[i];
D[i] = E[i] * F[i];
}
Apply loop distribution:
// First independent loop
#pragma omp parallel for
for (int i = 0; i < N; i++) {
A[i] = B[i] + C[i];
}
// Second independent loop
#pragma omp parallel for
for (int i = 0; i < N; i++) {
D[i] = E[i] * F[i];
}

Variable Scopes and Synchronization
Commonly seen variable usage in code with loops:
| Variable usage | Concept | Scope | Example |
|---|---|---|---|
| Read Only | Variables that are only read inside the loop and not modified can be safely declared as shared. Since their values remain constant, multiple threads can access them concurrently without causing data inconsistencies. | Shared | Constants, input arrays that are not modified. |
| Loop Index Variables | Loop index variables are inherently thread-specific in OpenMP parallel loops and are considered private by default. Each thread works on its own set of iterations, so the loop index should not be shared. | Private | The variable i in for (i = 0; i < N; i++). |
| Temporary Variables in Loop | Variables that are defined and used within the loop body and do not need to retain their value between iterations should be private. This ensures that each thread has its own instance, preventing interference between threads. | Private | Temporary computation variables, accumulators used within a single iteration. |
| Reduction Variables | Variables that accumulate results across iterations (like sums or products) require special handling. They should be declared in a reduction clause to ensure that each thread maintains a private copy during execution, which are then combined at the end. | Private (Reduction) | A variable sum used to accumulate results. |
| Modified Shared Variable with Proper Data Parallel | Variables (usually elements inside array) that are assigned to threads, each thread only access a specific part of the data. Each thread will only access their own parts, and will not access element assigned to other threads. | Shared (Data Parallel) | Array elements A[i] being written in for (i = 0; i < N; i++). |
| Modified Shared Variables | Variables that are written by multiple threads and need to maintain a consistent state across threads should generally be avoided or protected using synchronization mechanisms (like critical sections or atomic operations). If possible, redesign the algorithm to minimize shared writable variables. | Private (Critical Section) | Shared data structures that threads need to update |
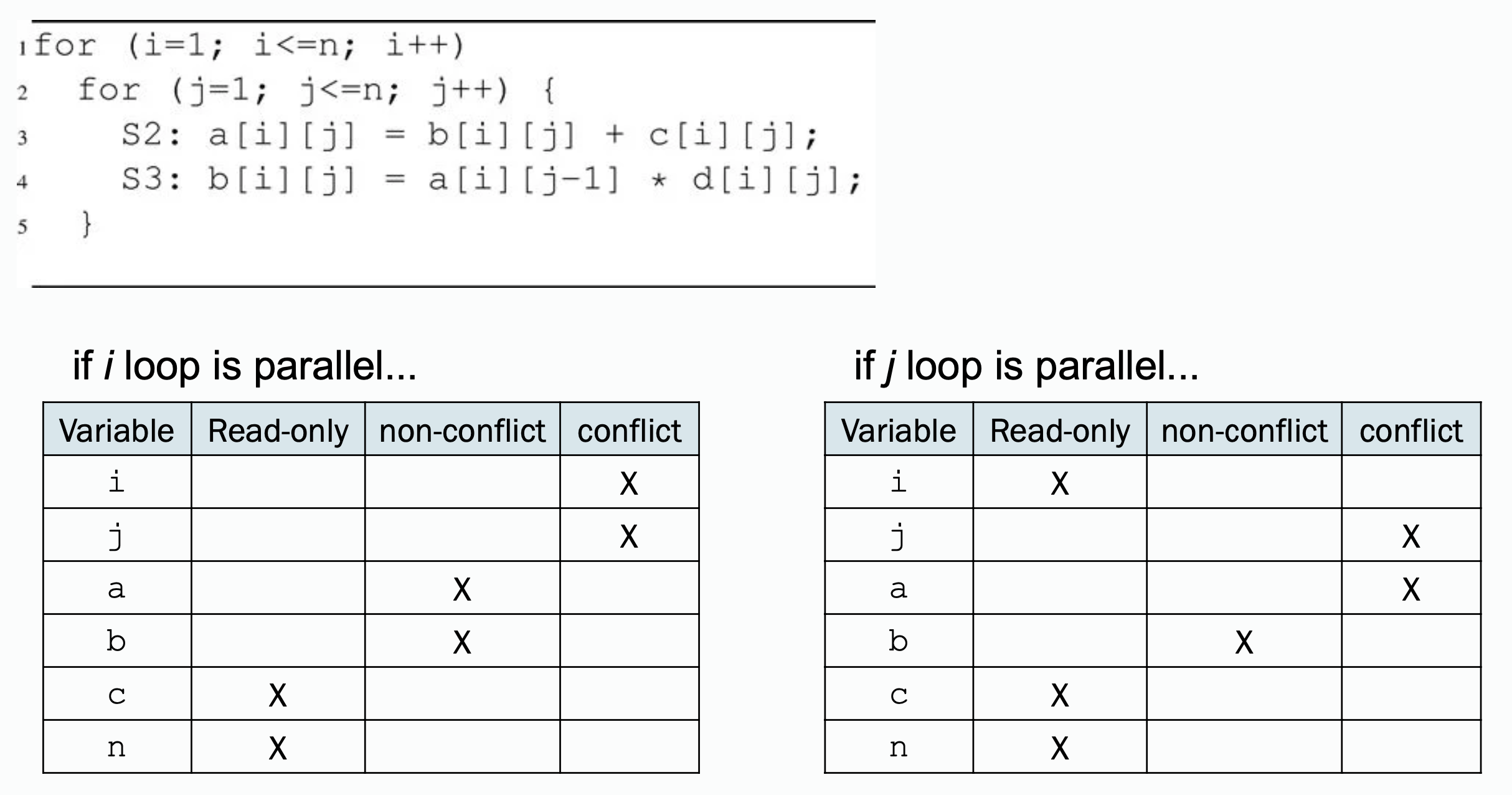 Explained:
Explained:
- conflicts will be there for or if or loop is parallel;
- and are being written so they are not read-only;
- if loop is parallel,
Variable Privatization (OpenMP)
To solve the conflicts for a variable, there are some conditions to refer to:
- (x) Variable written by a task before being read by the same task.
- (o) Variable can be initialized for each task independently (without waiting for a previous task).
Reduction (OpenMP)

Variable reduction in parallel programming models adds up different parts of A[i] on different processors. Say, we have unlimited processors, therefore:
A[i]is split into pairs of them, each of the pair is sum up by a processor and produce result, that means differentaves are produced during the first step- For the produced
aves, processors add up each pair of them, and produce results - Repeat the process until there is only one ave left
Synchronization is needed on each level of reduction, to make sure the previous parallel step has already finished. But you do not need a Barrier operation(see below) here, the synchronization mechanism should be at system level not program level in OpenMP(while in CUDA programming you need manual synchronization within the reduce kernel).
Critical Section (OpenMP)

Critical section creates some kind of "lock" on variable that it only one thread is allowed to execute a statement on such a variable,
Barrier (OpenMP)
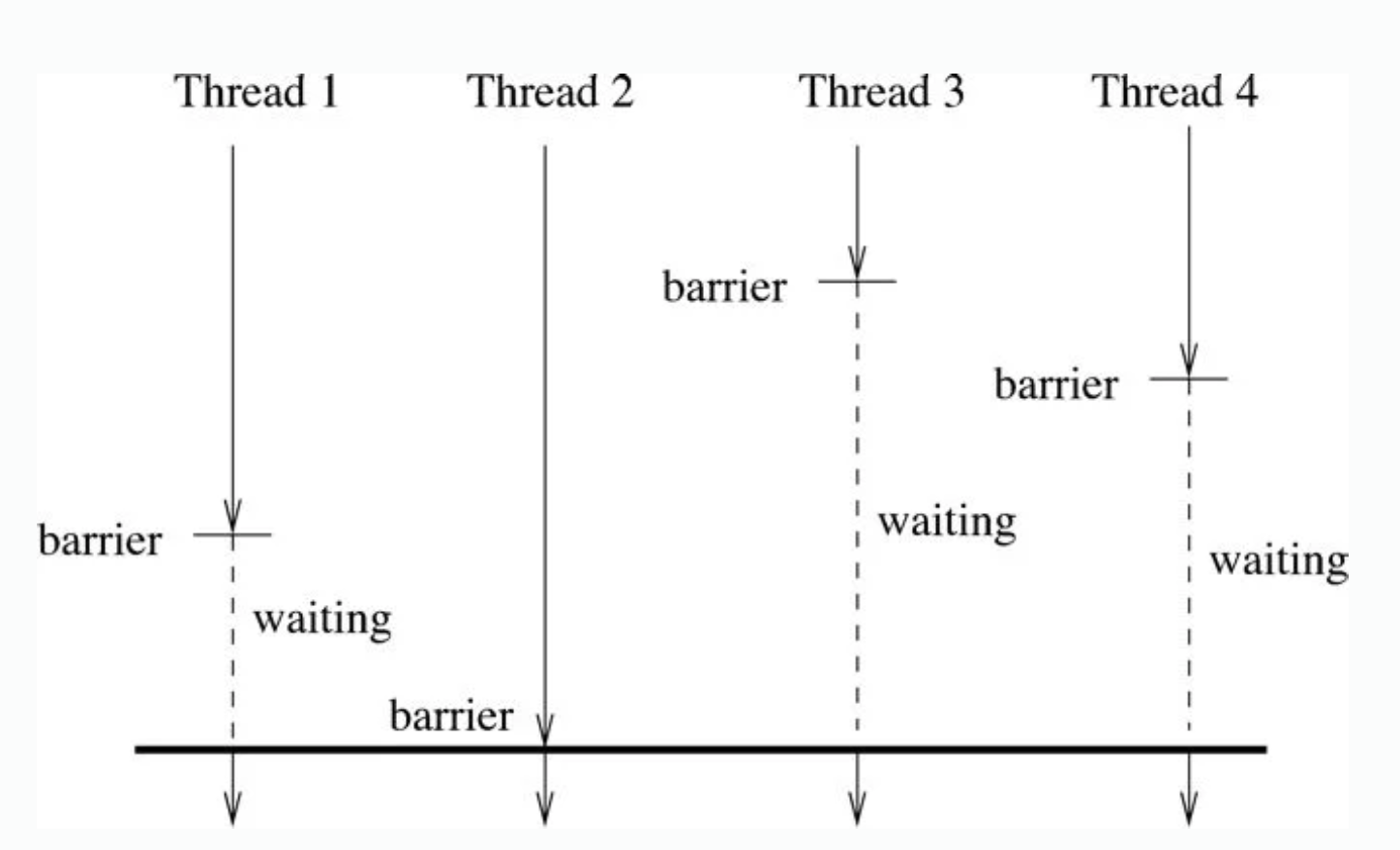
Barriers are something like thread synchronization, it asks every thread to reach the barrier point before they continue.